http
网络请求,协议
[TOC]
介绍下网络协议分层?
OSI七层模型:
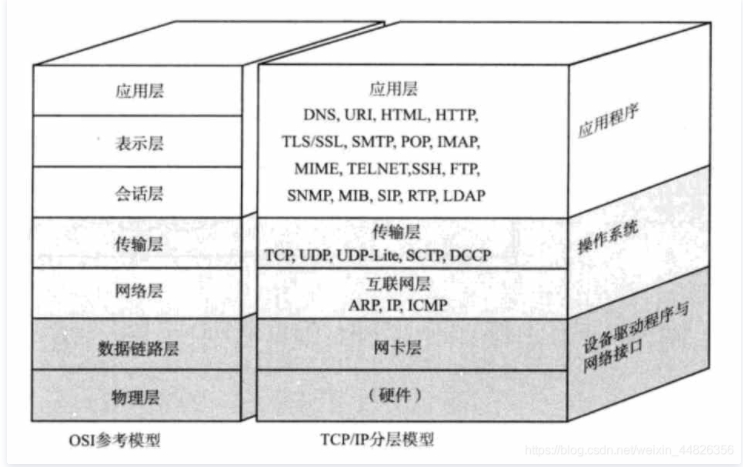
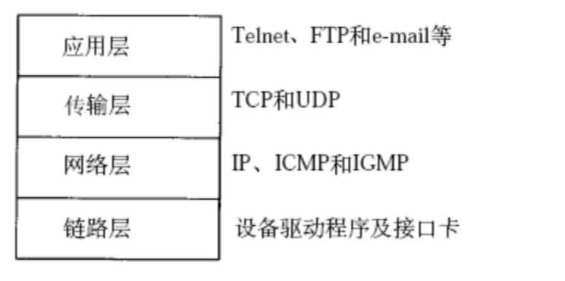
TCP/IP 四层模型:
参考资料:
put,patch,post区别?
相同点:三个都是用于修改请求
不同点:
**put 与 post 区别 **
put:等幂性,连续调用一次/多次效果相同,无副作用; 使用场景:修改用户名接口, 提交多次,结果也是一样的;
post:是非幂等性的,创建博客接口,多次提交创建多个
put 与 patch区别
put:直接资源覆盖型的使用put, 比如分销模块化接口;
patch: 对已知文件进行局部更新,比如修改用户名;
常见的网络协议有哪些?
HTTP协议: 超文本传输协议,规定了浏览器和万维网服务器互相通信的规则。使用:浏览网页,网页下载
FTP协议:文件传输协议。使用:FTP服务端上传软件
SMTP协议:简单邮件传输协议,在其之上指定了一条消息的一个或多个接收者,然后消息文本会被传输。使用:foxmail
NFS协议:网络文件系统,文件共享的协议。用户和程序可以像访问本地文件一样访问远端系统文件。使用:Linux搭建网盘
UDP协议:用户数据报协议,支持多方数据传输 使用:DNS ,QQ
TCP/IP协议:传输控制协议,每一条TCP只能点对点传输 使用:http底层技术,QQ((UDP协议为主,TCP协议为辅助),websocket
Telnet协议:远程登陆,使用明文传输数据,有一些安全问题,慢慢被淘汰。连接客户端推荐使用SSH协议
参考资料:几种常见的网络协议
UDP与TCP的区别?
UDP协议:无连接,尽最大可能交传,没有拥塞控制、面向报文,支持一对一,一对多,多对多交互通信。
TCP协议:面向连接,提供可靠交付,有流量控制,拥塞控制,提供全工控制,面向节节流,每一条TCP连接只能点对点的(一对一)
DNS解析过程,及优化方案?
定义:通过域名解析找到服务器主机IP地址,方便通讯
查找该域名对应的IP地址、重定向(301)、发出第二个GET请求
查找流程:
浏览器查找DNS缓存
本机(系统级别)查找DNS缓存
dns服务器
-自动获取DNS服务器地址(局域网id)
路由器(做dns转发,也会有缓存)
运营商ISP分配的 (直接连接),部分运营商会通过dns劫持做广告植入
指定DNS服务器地址(首选,备选)--优点:解析快/无污染/防劫持
google dns
ali/baidu/open/114 DNS
host定义的配置文件
本地域名DNS服务器()-->根域名服务器--> COM顶级域名服务器-->x.com域名器
参考资料:在Windows中,选择TCP/IPv4协议设置中的“自动获取DNS服务器地址”,计算机究竟做了什么?
一个页面从输入 URL 到页面加载显示完成,这个过程中都发生了什么?
下面以HTTP协议为例:
在浏览器输入 URL
浏览器查看缓存
未缓存:发起新请求
已缓存:
新鲜:直接提供给客户端
不新鲜(过期):否则与服务器进行验证
判断新鲜(是否过期)的http字段 Expires 和
Expires (HTTP1.0) : 值为一个绝对时间表示缓存新鲜日期
Cache-Control (HTTP1.1):max-age=, 值为以秒为单位的最大新鲜时间
浏览器解析URL(获取 协议/主机/端口/path)
浏览器组装一个HTTP(GET)请求报文
浏览器获取主机IP地址
浏览器缓存
本机缓存(操作系统级别)
hosts文件
路由器缓存
ISP DNS缓存
DNS递归查询(可能存在负载均衡导致每次IP不一样)
打开一个socket与目标IP地址,端口建立TCP链接
过程
1.客户端发送一个TCP的 SYN=1,Seq=X 的包到服务器端口 (你能听到我说话吗)
2.服务器发回:SYN=1,ACK=X+1, Seq=Y 的响应包 (听到了,你能听到我说话吗)
3.客户端发送: ACK=Y+1,Seq=Z (听的到)
参数解析
Seq(sequencer):序列号,不传递实现内容
SYN(synchronous):建立联机
ACK(acknowledgement): 确认
TCP链接建立后发送HTTP请示
服务器接受请求并解析,将请求转发到服务程序,如虚拟主机使用HTTP Host头部判断请求的服务程序
服务器(nginx,apache...)接受请求并解析
服务程序(真正的服务器,自建/阿里云服务器)
服务器检查HTTP请求头是否包含缓存验证信息,如缓存新鲜,返回304状态码
处理程序(后端代码)读取完整请示并准备HTTP响应(可能需要查询数据库操作)
服务器将响应报文通过TCP连接发送回浏览器
浏览器接收HTTP响应,然后根据情况选择关闭TCP连接或者保留重用,关闭TCP连接的四次挥手
浏览器检查响应状态码:是否为1/3/4/5XX,这些情况与2XX不同
判断资源能否缓存,进行缓存
对响应进行解码(eg: gzip)
根据资源类型决定如何处理(假设资源为html)
html文档解析(dom,cssom,js解析)过程
显示页面
浏览器这边做的工作大致分为以下几步:
加载:根据请求的URL进行域名解析,向服务器发起请求,接收文件(HTML、JS、CSS、图象等)。
解析:对加载到的资源(HTML、JS、CSS等)进行语法解析,建议相应的内部数据结构(比如HTML的DOM树,JS的(对象)属性表,CSS的样式规则等等)

参考资料:
从浏览器地址栏输入 url 到显示页面的步骤(以 HTTP 为例)
从输入URL到页面加载的过程?如何由一道题完善自己的前端知识体系!
get和post有什么区别?
区别:
【数据传输方式不同】
get参数是在url
优点:
浏览器可缓存数据(适合一些静态资源:js/css/img/font/html等,还有一些枚举项的查询)
url方便保存/分享
缺点:
容易被拦截、篡改
post 是放在request body里面
优点:
post相对来说安全一些,参数不暴露在url上 (比如:用户账号密码,敏感的查询信息)
【请求长度】
get参数长度有限制,这个限制不是http协议规定的,而是浏览器对url进行的限制,所以不同浏览器的限制不同
Post 无限制
【数据类型不同】
get只允许ASCII字符
POST无限制
【特性不同】
GET是安全(指只读特性,使用这个方法不会引起服务器状态变化)且幂等(指同一个请求方法执行多次和仅执行一次效果完全相同)
POST是非安全非幂等
相同点:
底层都是TCP/IP,Get产生一个TCP包,post产生两个
浏览器加载解析渲染过程 ?
【自上而下】进行加载,并在加载过程中进行解析渲染; 解析过程
html解析成一个dom树,dom树的构建过程是一个深度遍历过程 ;当前节点所有子节点渲染后才会去构建当前节点的下一个子节点 ;
css解析成css rule tree;
根据dom树和CSSOM(css对象模型)来构造 rendering tree;


dns查询层级?
从浏览器缓存中查询(一般是2-30分钟)
从操作系统缓存中查询
从路由器中查询DNS缓存
ISP中查询DNS缓存;
域名服务器迭代查询,根据返回的地址逐级向上查询。www.google.com->本地dns服务器查询的结果 101.1.1.1->101.2.2.2->查询的结果返回到本地dns服务器->发送给客户端

说明 :客户端到本地服务器属于递归查询,DNS服务器属于迭代查询
常见的web服务器有哪些?
运行web应用,提供网上信息浏览服务
Apache:世界上用的最多的web服务器,开源,支持跨平台应用(unix,windows,Linux),属于重量级产品,内存消耗大,速度、性能上不通讯其他轻量级web服务器
Nginx: 高性能HTTP 和 反向代理服务器
Apache:开源、支行servlet和JSP web应用软件,基于Java的web应用软件容器
Microsoft IIS: 只能运行在windows平台上
ajax与fetch
ajax 的实现原理?
Ajax(Asynchronous JavaScript and XML)指的是通过JavaScript使用XMLHttpRequest对象来异步获取数据并更新页面的技术。其实现原理可以简单描述为以下几个步骤:
【实例化xhr对象】创建XMLHttpRequest对象,也就是创建一个异步调用对象.
【设置请求方法和URL】
【发送HTTP请求】
【监听请求变化】监听响应变化,并操作界面
ajax(XMLHttpRequest)与fetch区别?
相同点:都是异步请求的api
fetch优点:
【原生支持】浏览器原生支持的api,写起来比ajax简单
【基于promise】不要写回调地狱了,(jquery 1.5版本后也支持了)
【默认不带cookies】需要手动添加
fetch缺点:
【兼容性较差】目前兼容性还不是很好,但它是未来 (可以引入polyill,让不支持的浏览支持fetch api)
【请求无法取消】这是因为fetch基于promise,promise 无法做到这一点,超时无法取消,造成了对流量的浪费
【更加的底层】只对网络请求报错,对400,500都当做成功请求,需要二次封闭
【请求进度状态无法监听】而XHR可以
fetch如何处理跨域?
服务端要支持cors 才能得到数据
CORS cors是"Cross-Origin Resource Sharing"的简称,是实现跨域的一种方式,相对于其他跨域方式,比较灵活,而且不限制发请求使用的method,以下从几种情况分析cors使用。
后端代码
参考资料:
fetch和axios有什么区别?
相同点:
都是用来发送请求的工具
不同点:
底层不同:fetch是ES6原生的api, axios是基于Promise封装的请求库,需要先引入才能使用。

axios功能更强大
【适用面更广】axios支持在浏览器和Node层中使用,而fetch只能在浏览器中使用。
【兼容性】axios兼容性更好,fetch api在某些浏览器不支持
【功能更丰富】
axios支持拦截器功能:可以拦截请求和响应,在发送和接收数据时做统一处理。
axios支持取消请求:在复杂请求时有用
axios支持更多的配置选项
axios返回更丰富的错误信息:在处理错误时,提供了更丰富的错误信息:HTTP错误状态码、错误信息等。
为什么axios post会发两次?
这个和跨域有关系
第一次:预请求,不携带数据,判断服务器能否跨域;在预检请求的返回中,服务器端也通知客户端,是否需带身份凭证(cookies,http认证相关数据); 状态码204
第二次:携带真实的数据,发送请求;状态码200

产生的原因:
使用了非简单请求(not-so-simple request)
使用了非head, get ,post 请求,比如:PUT,DELETE
或者 content-type 使用了 application/json; 而不是application/x-www-form-urlencoded、multipart/form-data、text/plain
参考资料:
https://cloud.tencent.com/developer/article/1542037

dns查询层级?
从浏览器缓存中查询(一般是2-30分钟)
从操作系统缓存中查询
从路由器中查询DNS缓存
ISP中查询DNS缓存;
域名服务器迭代查询,根据返回的地址逐级向上查询。www.google.com->本地dns服务器查询的结果 101.1.1.1->101.2.2.2->查询的结果返回到本地dns服务器->发送给客户端

post 请求中 content-type的几种类型?
application/x-www-form-urlencoded:最常见的方式,传输数据:title=test&sub%5B%5D=1&sub%5B%5D=2&sub%5B%5D=3
jquery axios默认使用的就是这种方式
浏览器原生form如不设置enctype属性
multipart/form-data: form表单中使用,需要设置
application/json:告诉服务器端,消息主体是序列化后的json字符串
text/xml:使用http作为传输协议,xml作为编码规方式的远程调用规范
http&https
HTTP有哪些方法?
一、HTTP1.0请求方法:
get: 请求服务器发送某些资源
post:发送数据给服务器
head:请求资源的头部信息,并且这些头部收不到http get方法请求时返回的一致
二、HTTP1.1 新增请求方法:
options:用于获取目的资源所支持的通信选项
put:新增资源,是幂等性的 ( )
delete:删除指定的资源
trace:回显服务器收到的请求,主要用于测试或诊断
connect:预留给能够将连接改为管道方式的代理服务器
patch: 对资源应用部分修改
http2的优点?
1)二进制分帧
HTTP/2中,同域名下所有通信都在单个连接上完成,该连接可以承载任意数据的双向数据流。
2)多路复用
同域名下所有通信都在单个连接上完成
单个连接可以承载任意数量的双向数据流
3)Header压缩
http3的优点?
对TCP协议进行改造
google基于UDP协议开发了QUIC协议,并且使用在HTTP/3上
优点:
0-RTT:缓存当前会话的上下文,重连时只要传递给服务器端验证通过就可以了
多路复用:虽然HTTP/2已经支持,但是TCP协议终究没有这个功能,但是QUIC原生支持,并且传输的单个数据流可以保证有序交付且不会影响其他数据流,解决了TCP之前的问题
向前纠错机制:多发数据,避免重传,只能使用在丢失一个包的情况下,多个包丢失还得依靠重传的方式
参考资料:https://blog.fundebug.com/2019/03/07/understand-http2-and-http3/
http与https有什么区别?
https增加了数据加密,比http更安全
https 默认使用443端口,http是80端口
https相对比http慢一些,因为为加/解密这个过程
https需要向CA机构申请证书;
https加密过程?
https=http+SSL/TSL(加密层)
加密的分类:
对称加密:通信双方都使用同一个秘钥进行解密,
优点:简单
缺点:无法解决首次把秘钥发给对方的问题,容易被黑客拦截秘钥
eg: 特务暗号
非对称加密:
优点:安全性高
缺点:过程繁琐,慢
https采用的解决办法:结合两种加密方式(两端都可以开锁的保险柜,任一方有钥匙都可以)
将对称加密的密钥使用非对称加密的公钥进行加密,然后发送出去
接收方使用私钥进行解密得到对称加密的密钥
然后双方可以使用对称加密来进行沟通
https主要分为三个阶段
验证证书,生成秘钥阶段
使用公钥,加密数据阶段
使用私钥,解密数据阶段
参考:
https://cloud.tencent.com/developer/article/1643914
http三次握手四次挥手?
三次握手:是指在建立一个TCP连接时,需客户端和服务器总共发送3个数据包;
参考:https://cloud.tencent.com/developer/article/1643914


http请求报文解剖?
http请求报文主要由三部分组成,
报文行/请求行:
-【协议】定义请求协议post/get
【地址】 请求url
【版本】http协议及版本
报文头:缓存控制,cookies设置,accept告诉服务端接收什么类型参数,referer发送请求的地址来源;
报文体:
-【参数】请求的参数
http/2协议中, connection和 keep-alive是被忽略的,在其中采用其他机制来进行管理
可以使用postman抓包工具进行原始数据抓取

HTTP 头部字段(请求头/响应头)有哪些?
特别说明:加*说明是必选字段
一、请求头:
user-agent (*) : 客户端程序信息 //可判断什么浏览器,什么webview容器
referer(*): 请求信息的来源 //可以用来拦截非法cdn资源引用,和跨站请求伪造攻击
accept: 客户端能处理的文件类型
*/* 代表所有
text/html //html
image/webp,image/apng //图片
accept-encoding : 客户端能够接受的内容编码方式(某种压缩算法)
gzip
br
compress
deflate
accept-language: 客户端能够解析的语言
de
de-CH
en-US,en;q=0.5
dnt : 不要追踪 //do not track 隐私保护,不要给我推个性化广告,君子协议不一定生效
connection: 连接管理、逐条首部, 不与http2一起使用
keep-alive 可重新连接,减少资源消耗,缩短响应时间,一般会设置服务端超时时间,同时会设置最大请求数,越过也会自动关闭,要服务端支持才行; 允许请求和应答的http管线化,降低拥塞控制(TCP连接减少了),报告错误无需关闭TCP连接
close //默认值
sec-fetch-* //网络请求的元数据描述,服务端精确判断请求的合法性,2019年发布的草案,目前浏览器兼容性不高
Sec-Fetch-Dest: image Sec-Fetch-Mode: no-cors Sec-Fetch-Site: same-origin
If-Modified-Since 服务器发过来的最后修改时间 ,缓存时间判断使用,如果时间一致,http状态码304(不返回文件),客户端直接显示本地缓存文件;如不一致,就返回http状态码200和新的文件内容,客户端接到之后,丢弃旧文件,缓存新文件
cache-control: 控制缓存
no-cache //无缓存,浏览器开启 disable cache会同现
二、响应头:
server(*) : 响应的服务器 //nginx,apache
accept-ranges(*) //标识服务器自身支持的请求单位 //bytes, none
Access-Control-Allow-Origin : cors跨域请求头 // *允许所有域名跨域请求
content-length(*): 资源大小
content-type(*): 资源类型
status:响应状态 //304强缓存
cache-control:: 缓存控制
max-age=691200 //缓存时间,后面的数据是秒
date(*): 资源最新获取时间 // 不使用缓存的情况下,每次刷新会变
expires: 到期时间
last-modified: 资源上次修改的时间
age : 表示对象在缓存代理服务器中存贮的时长,单位秒
eTag: Etags类似于指纹,比较etags可快速确认资源是否改变,可能被某些服务器跟踪
x-request-id: 由客户端随机生成,帮助排查问题使用
参考资料:
http响应报文?
响应行:协议版本、状态码或状态码的原因短语组件: eg : HTTP/1.1 200 OK
响应头:响应部首组成
响应体:服务器响应的数据

响应头部的信息?
请求头部信息(request header)
接收的格式,来源,语言编码,浏览器信息,是不使用缓存,超时时长和最大请求数, cookies(keep-alive:timeout=5,max=1000)
http/2协议中, connection和 keep-alive是被忽略的,在其中采用其他机制来进行管理
2.响应头部信息(response headers)
内容压缩格式/长度/类型:gzip/1000/text、html/日期/服务器/
http状态码有哪些,分别代表什么意思 ?
1** 信息类:表示接收到请求并且继续处理;
2** 响应成功:动作被成功接收、理解、接受
3** 重定向:为了完成指定的动作,必须接收进一步处理
4** 请求包含错误语法或不能正确执行;
5** 服务器错误:服务器不能正确执行一个正确的请求
浏览器缓存
浏览器缓存分类?
1) 强缓存 (状态码304)
直接从本地读取,不会发起请求到服务器;
2)协商缓存 ( 状态码200)
从服务器端缓存中读取,会发起请求到服务器
from memory cache 和 from dist cache区别?
相同点:都是协商缓存(不访问服务器),状态码都是200;
不同点:
Memory cache: 从内存中读取缓存,当浏览器关闭后,进程被kill了,缓存将清除
Dist cache: 从硬盘中读取缓存,当kill浏览器进程,缓存还在
判断标准:
根据内存闲置情况判断是否放入内存,还是放入硬盘;
浏览器三级缓存原理?
先读缓存内存 from memory cache
读硬盘缓存: from dist cache
请求服务器资源
把从服务器的资源缓存在内存和硬盘中
eg:
访问一张图片的缓存过程 :
首次加载,状态码200
退出浏览器,再次加载(需要服务器之前设置过缓存),from dist cache ,从硬盘中获取
再次刷新页面,200 from memory cache 从内存中读取

参考资料:https://www.zhihu.com/question/64201378
如何开启浏览器强/协商缓存?
在服务器端(nginx,Apache...,大部分web服务器默认开启会协商缓存)设置Expire字段,浏览器会读取,再进行缓存控制

通过返回的header
Cache-Control: 是否缓存,及缓存时间, 优先级高于expires,表示相对时间
Cache-Control:no-cache //先缓存本地,但是在命中缓存之后必须与服务器验证缓存的新鲜度才能使用
Cache-Control: max-age=315360000 //缓存时间设置,单位s
Cache-Control: no-store 不会产生任何缓存
Cache-Control: public 可以被所有用户缓存,包括终端/cdn等中间代理服务器
Cache-Control: private 只能被终端浏览器缓存,不允许中继缓存服务器进行缓存
Expires: 过期时间,绝对时间,由服务器返回,expires受限于本地时间,如果修改了本地时间,可能造成缓存失效
Etag(判断返回字段:If-none-match): 给定URL资源更改,会生成新的ETag,类似指纹,通过比较etag能快速确认此资源是否变化
Last-modified (判断返回字段 : If-modified-since): 最后更新时间,协商缓存会使用
参考资料:
强/协商缓存判断流程?
【是否存在缓存?】Cache-Control 字段判断
【缓存是否过期?】Cache-Control、Expires 字段
【文件指纹是否相同?】判断ETag 指纹是否一致,向服务器请求 If-none-match, 服务器返回200 or 304
【更新时间是否相同?】判断Last-modified,向服务器请求 if-modified-since ,服务器返回200 or 304
服务器返回304读取本地,200请求响应协商缓存

参考资料:
最后更新于
这有帮助吗?