其他
[TOC]
前后端鉴权有哪几种方式有什么区别?
一、http基础验签, http basic Authentication
运用场景:已经淘汰
**原理:**账号、密码登录(可简单加密)
**优点:**简单
**缺点:**不安全
二、session+cookies 机制
**运用场景:**老项目,非前后端分离(php, asp)
**原理:**服务端生成sessionId,经过加密后(可不加密)返回给客户端,以cookies的形式保存在浏览器中
优点:非前后端分离项目使用简单
缺点:
sessionId 存在服务器,占用一定的资源
所有的请求都会带 cookies浪费请求资源
浏览器才有cookies, 客户端没有,支持的范围少
三、token机制(也称令牌登录)
**运用场景:**主流新项目
**原理:**token经过一定的算法生成的,本身就包含登录状态,服务器经过事先定义好的算法解密判断是否有效
优点:
【不占资源】:token本身保存着登陆状态,不存在服务端,节省空间
【多端支持】不用存在cookies里,支持app等客户端使用
【更加安全】令牌隔一段时间是会变化的
四、oAuth开放授权
**运用场景:**第三方授权登录(QQ,微信,微博,github)
优点:
【无需注册】通过第三方授权联合登录,快速登录,用户体验好
参考资料: 关于前后端鉴权的几种方式
Npm 实现原理?
Npm 是node模块管理器
npm 安装模块的过程
执行 npm install
读取package的依赖
向注册的npm 服务器发送资源包请求,返回资源压缩包
把资源把请求放在当前文件的 node_modules文件夹中
参考资料:
http://www.ruanyifeng.com/blog/2016/01/npm-install.html
https://www.zhihu.com/question/66629910
https://zhuanlan.zhihu.com/p/286021449
如何提高Npm的安装速度?
代理服务器,
代理到国内服务器:比如阿里的服务器 cnpm
使用ssh之类的代理服务器提高下载速度 (也可以直接使用vpn,就不用设置了)
使用本地缓存
npm原生:npm install --cache-min Infinity ,
第三方:
npm-cache 代替npm: 比如 npm-cache install
使用 node_modules 作为缓存目录,而不是 .npm 缓存
代理服务器的设置
=======
Api 网关和 Nginx 有什么区别?
相同点:
都可以实现反向代理(路由转发,隐藏真实Ip)
实现负载均衡
过滤请求
不同点:
Nginx 采用服务器负载均衡进行转发
网关决定进入哪个真实web服务器
什么是API网关?
一个API网关接管所有的入口流量,类似Nginx的作用,将所有用户的请求转发给后端服务器;
API网关主要出现在微服务架构中
API网关的优点:
【逻辑重用】鉴权、限流、权限校验、熔断、协议转换(http-> Dubbo)、错误码统一、缓存、日志、监控、告警等
【新服务不用运维配置】后端新的微服务,申请域名,配置Nginx
【数据汇总】把所有服务聚合在一起,不用调很多接口获取数据(省去为每个微服务配置域名)
【格式转换】数据格式转换成方便前端调用的格式
【兼容性更强】
**不同协议请求:**后端微服务可能由不同语言编写,支持不同协议(http,dubbo,GRPC,GraphQL)
**不同认证方式:**cookies ,token
【方便重构】只需要修改网关代码,不需要修改每个客户端
API网关的风险:
【潜在风险】多引入一个组件,就多一个潜在故障的风险(高性能、移定的网关涉及到很多点)
构建高性能、稳定性的API网关的知识点:
服务调用:异步(推荐):基于性能考虑
优雅下线:节点挂了,自动下线
熔断降级:一个服务挂掉、响应严重超时不要影响到整个网关服务,特定接口错误进行降级由网关直接返回
性能:推荐使用异步
缓存:网关层面直接从redis获取数据,降低业务线压力,如果业务方节点挂掉,网关也能够返回自身的缓存
限流:
策略:简单计数、令牌桶 (其他维度:IP,用户,接口,url特定参数)
日志:所有请求都走网关,统计详细日志:耗时、请求方式;需要提供一个统一的traceId 方便关联所有日志
隔离
应用层面隔离:线程池、http连接池、redis等应用层面的隔离
业务场景:核心业务部署到单独的网关集群(与非核心业务隔离开)
网关管控平台:接入网关的流程简化、智能(参考阿里支、aws等提供的网关服务)
其他:接口Mock,文档生成、sdk代码生成,服务治理...
未使用网站前:
使用网关后:
参考资料:
前端如何做API网关?
基于node.js 的网关:
http-proxy: 软件包简单地代理对特定服务的请求
express-gateway : 更多丰富功能
参考资料:
设计一个组件你会考虑哪些问题?
前端组件设计原则:
细粒度的考量:单一职责
通用性的考量:与业务解耦,但又要服务业务
参考资料:
常用的数据结构有哪些?
数据结构是指相互之间存着一种或多种关系的数据元素的集合,和该集合中数据元素之间的关系组件。
数据结构,是计算机中存储、组识数据的方式
常用的数据结构
一、栈(stack)
栈是一种特殊的线性表,仅能在线性表的一端操作,栈顶允许操作
特点:先进后出
应用场景:
代码执行过程,js event loop
二、队列(Queue)
队列是一种线性表,队列可以在一端添加元素,在别一端取出元素
特点 :先进先出
使用场景:
多线程阻塞队列管理
三、数组(Array)
数组是可以在内存中连续存储多个元素的结构,在内存中折分配也是连续的
四、链表(Linked List)
特点:
非连续、非顺序的存储结构
逻辑顺序:通地链表的指针地址实现
包含两个结点:1. 存储元素的数据域;2.指向下一个结点地址的指针域
无需初始化容易,可以任意加减元素
分类(根据指针的指向):
单链表
循环链表
双向链表
五、树(Tree)
联想:类似思维导图的结构
特点:
每个节点有零个或多个子节点
没有父节点的节点称为根节点
每一个非根节点有且只有一个父节点
应用:
二叉树:平衡二叉树、红黑树,B+树等
六、图(Graph)
分类(按照顶点指向的方向):
无向图
有向图
七、堆
可以被看做一棵树的数据对象
联想:有顺序的二叉树
特点:
堆中某个节点的值总不大于或不小于其父节点的值
堆总是一棵完全二叉树
应用:
数组排序(堆排序)
八、散列表(哈希表)
根据关键码和值(key和value)直接进行访问的数据结构,通过KEY和 value 来映射到集合中的一个位置,这样就可以很快找到集合中的对应元素
特点 :
基于数组衍生的数据结构
左边是一个数组,数组的每个成员包括一个指针,指向一个链表的头(可能为空/可能多个)。根据元素的特征把元素分配到不同的链表中去,也是根据这些特征,找到正确的链表,再从链表中找出这个元素
应用:
java中的集合类借鉴哈希原理构造(HashMap,Hash Table)
参考资料:
前端错误监控原理?
错误分类:
资源加载错误
错误捕获
object.onerror (img ,script)
performance.getEntries()
Error事件捕获
代码错误
错误捕获:
try/catch
window.onerror
错误上报方式:
ajax
image
特别说明:
跨域的js error需要捕获的处理方式
script标签 增加 crossorigin属性
js设置 资源响应头(CORS): access-control-allow-origin:*
响应式图片实现方式?
根据窗口尺寸的改变,动态显示不同大小的图片
js 监听 resize事件,动态修改
img srcset 方法 //兼容性不好
picture 标签 -> source
svg //矢量图,一般是icon才会使用
+运算符的工作流程?
【转原始值】如果操作数是对象,先转换成原始值
【字符优先】如果有一个是字符串,其他操作数都转换为字符串并执行连接
【数字累加】否则:所有操作数都转换为数字并执行
=== 运算符判断相等的流程是怎样的?
【判断类型】判断是否相等
【都是null/undefined】判断是否相等
【都是boolean类型】判断是否相等
【有一个NaN】则不相等
【都是数值】判断是否相等,注意:-0等于0
【都是字符串】:判断长度/内容/编码
【引用类型】:指向相同对象则相等
什么是渐进增强?
保证所有人都能访问页面的基本内容和功能,同时为高级浏览器和高带宽用户提供更好的用户体验
核心原则:
所有浏览器都能访问基本内容
所有浏览器都能使用基本功能
所有内容都包含在语义化标签中
通过外部CSS提供增强的布局
通过非侵入式、外部js提供增强功能
有哪些复杂的前端项目?
强交互(逻辑复杂,状态多)
工具类(web office, web ps, web IDE)
web游戏
在线IM
可视化建站
图形可视化 (定制图表类)
canvas,webGL (游戏,web PS)
单点登录如何实现?
定义:将多个子系统的认证体系打通,实现了一个入口多处使用
实现方案:
一、共享session
二、基于OpenId
三、基于Cookie的openId存储方案
四、B/S多域名环境下 的单点登陆处理
node开发的一些小工具,应用?
把打包后的资源上传到cdn
爬虫开发
定制cli
pm2有什么用?
pm2是一个进程管理工具;
带有负载均衡功能的node应用进程管理器;
pm2管理node服务的优点:
自带负载均衡
程序崩溃自动重启
支持性能监测
程序崩溃自动重启
文件如何做断点续传?
主要分为三步:
保存文件唯一性标识(通过let md5code=md5(file))
切割文件;html5的新特性,使用slice方法分割;
分段上传,每次上传一段,根据唯一性标识判断上传进度;
主要思路是把一个大的文件拆分成几个小的文件,分批上传;
如果中断了,从本地存储里面判断已经上传到第几个了,
如果所有文件都上传完了,后台再把文件合并存入数据库中;
通过什么做到并发请求?
event loop 事件轮询,setTimeout, 异步请求(ajax,资源加载)
什么service worker?
sevice worker 本质是充当web应用程序和浏览器之间的代理,也可在网络可用的情况下作为浏览器和网络间的代理;
用户在离线的情况下,也能通过缓存访问网页
拦截并修改访问的资源和请求,细粒度的缓存资源 ;
主要有以下特性:
只支持https服务,在firefox隐藏模式下 service worker不可用;
消息推送;
后台同步,启动一个serive worker 即使没有用户访问特定站点,也可以更缓存 ;
性能增强,预读取资源
cookies和session有什么区别?
cookies和session都是做本地存储的;
区别如下:
cookies存放在客户端,session存放在服务端;
session默认存在服务器的一个文件中,而不是内存中;
session一般需要一个session_id,来查找相关数据,session_id一般通地客户端中的cookies和url中取值;
你对AST了解多少?
AST是抽象语法树,用来描述源代理的树形结构,类似html中dom;
展现形式看起来像一个对象;
使用场景:
webpack的babel代码转换:es6/7 => es5;
浏览器会把js代码转换成抽象语法树,再转换成字节码或者直接生成机器码;
如何判断当前脚本是运行中Node端还是浏览器端?
node没有window对象,所以可以使用这个全局变量来判断当前的环境。
如果直接在node中使用 if(window){}来判断会报错。可以使用typeof window来判断
安全
XSS跨站脚本攻击(Cross-Site Scripting)?
跨站脚本攻击,是代码注入的一种方式,它允许恶意用户将代码注入到网页上,其他用户在浏览网页时,就会受到影响
分类(按攻击来源):
一、存储型(存在数据库中)
攻击步骤
【提交恶意代码】:将恶意代码提交到目标网站的数据库中, 比如:发帖,评论,私信,web聊天框
【请求恶意代码】:用户打开网页,服务端取出恶意代码,拼接在HTML中并返回给浏览器
【浏览器解析恶意代码】:浏览器下载完成后,开始解析
【执行恶意代码】:窃取用户数据(用户账号密码),冒充用户行为调用目标网站接口执行攻击者指定操作(转账,清空数据库)
二、反射型(恶意代码存在URL中)
统计步骤过程如存储型,只是恶意代码的存储位置不一样,比如:网站搜索,跳转
【提交恶意代码】在url上,后端获取到url的script标签做为参数,拼接在页面上返回给页面
【浏览器请求/解析/执行 恶意代码】game over
eg:
http://xxx/search?keyword=">alert('XSS');
三、DOM型:
DOM型XSS攻击和前两种的区别:DOM型XSS攻击中,取出和执行恶意代码由浏览器完成(react,vue中的模板渲染引擎已经内置了处理DOM XSS攻击的措施),属于前端JS自身的安全漏洞。而其他两种XSS属于服务端的安全漏洞(服务端要做转义后渲染输入,拼接html)
解决方案
一、预防存储型和反射型攻击
【对HTML做充分转义】:比如常用的模板引擎内置转义器:ejs,但是这种模板引擎并不完善,要完善XSS防护措施,需要更完善的更细致的转义策略
【纯前端渲染】,把代码和数据分隔开
二、预防DOM弄XSS攻击
【DOM操作方法选择】在使用InnerHTML,outerHTML,document.write时要特点小心,不要把不可信的数据作为html插入到页面中,尽量使用 .textContent, .setAttribut()等
【VUE/React技术栈】:尽量不使用 v-html/dangerouslySetInnerHTML功能,就在前端render阶段避免innerHTML,outerHTML的 XSS隐患
DOM中的内联事件监听器,如: location/onclick/onerror/onload/onmouseover等,<a>标签的href属性,js中的 eval、settimeout等,都能把字符串作为代码运行
其他方案
【HTTP-only Cookie】: 禁止js读取某些敏感cookie,攻击都完成XSS注入后无法窃取此Cookie
【验证码】:防止脚本冒充用户提交危险操作(删除全部,转账)
CSRF跨站请求伪造攻击?
CSRF(Cross-site request forgery):攻击者诱导用户进入第三方网站,向被攻击的网站发送跨站请求。利用用户在被攻击网站已经获取的注册凭证,绕过后台的用户验证,达到冒充用户对被攻击网站某项操作的目的;
CSRF攻击流程:
用户在A网站登录了
诱导用户访问B网站
B网站向A发送一个请求 ( a.com/act=xx ),浏览器会默认携带 A网站 的cookie
A网站收到请求后,对请求进行验证,确认是用户的凭证,误以为是用户发送的请求
A网站以用户的名义执行了 act=xx的命令
攻击完成
CSRF分类:
GET类型:一个url地址,可以是一张图片,自动发送; eg: <img src=http://wooyun.org/csrf.php?xx=11 />
POST类型:js自动提交表单的形式,只在诱导网站提交,危害比GET小
链接类型的:a标签链接,触发条件要用户点击才可以,eg: 恶意图片,广告形式的链接
CSRF特点及预防手段
特点:
CSRF(通常)发生在第三方域名
CSRF攻击者不能获取到Cookie 等信息,只能使用
预防:
阻止不明外域的访问
同源检查(请求头header相关字段,判断来源域名):
origin
referer
Samesite Cookie
提交时要求附加本域才能获取的信息
CSRF Token
双重Cookie验证
介绍下https中间人攻击?
参考资料:
HTTPS中间人攻击实践(原理·实践) 简述HTTPS中间人攻击
HTTP header 中 host, referer, origin区别?
项目中如何处理安全问题?
XSS跨站脚本攻击:数据转
CSRF跨站请求伪造攻击token认证
开启https,避免数据劫持/监听
cookis设置path来限制防问的域名范围,开启secure
iframe滥用:iframe内容由第三方提供,默认情况下不受控制,他们可以在iframe中运行javascript脚本,带来一定安全问题
恶意第三方库
比如对抗 XSS/CSRF 的策略,账号风控策略、图片安全策略、恶意内容对抗策略、等等
跨站请求伪造:通过get请求进行数据操作,
数据库
NoSQL 与 sql 数据库的区别?
SQL:代表关系型数据库 (SQL≠关系型数据库,这里用作简写)
NoSQL: 代表非关系型数据库
参考资料:
阿里P8架构师谈:NoSQL和SQL的区别,NoSQL的使用场景和选型比较
mysql,mongodb 区别?
数据库模型
非关系型 (NoSql)
关系型
存储方式
虚假内存+持久化(速度快)
不同的引擎有不同的存储方式
查询语句
独特的Mongodb查询方式
传统sql语句
架构特点
可以通过副本集,以及分片来实现高可用
常用有单点,M-S,MHA,MMM,Cluster等架构方式
使用场景
文档
all
一、mysql
关系型数据库
优点
不同引擎上有不同存储方式
缺点:
海量数据处理慢
二、mongodb
基于分布式文件存储的开源数据系统
优点:
【快速】内存级存储,它将热数据存储在物理内存中(而不仅仅是索引和少部分数据)
【高扩展性】集群架构,可通过物理机的增加提高扩展性
【自身的failover机制】当主库遇到问题,副本集将选举出一个新的主库来继续提供服务
【json 的存储格式】适合文档格式的存储与查询
缺点:
不支持事务
占用空间大
无法进行关联操作
复杂聚合操作能过MapRReduce创建,速度慢
redis持久化缓存?
一、RDB持久化
将redis内存中的数据定时 dump(倾倒) 到磁盘中
redis fork一个子进程,先将数据写入临时文件
写入成功后,再替换之前的文件,用二进制压缩存储
优点:
【管理性强】:整个redis数据库最终备份成一个文件(方便管理,还原,压缩,转储)
【对服务影响最小】唯一要做的就是fork出子进程,之后的持久化工作由子进程处理
【启动效率高】记录的是源数据,而非数据操作
缺点:
【低可靠性】数据可用性得不到保障(定时写入的,可能数据还没同步就宕机了)
【大数据暂停服务】数据量大的情况下,fork子进程的操作可能会使服用短暂停止(通常几百毫秒)

二、AOF持久化
将redis的操作日志以文件追加的方式写入文件,只记录写、删除操作、查询操作不会记录(类似mySQL的Binlog日志)

优点:
【高可用】实时同步
缺点:
【体积较大】
【恢复数据慢】RDB省去了执行的步骤,直接导入源数据
缺点:
redis介绍?
高性能的key-value数据
一、redis特点:
redis 收不到其他 key-value数据缓存产品有以下三个特点:
默认数据存储在内存中,也可将内容内存中的数据保存在池盘中,做到持久化,重启时可再次加载
不仅仅支持简单的 key-value 类型的数据,同时提供多种数据结构
支持数据的备份,即master-slave模式的数据备份
redis支持的数据结构:
String 字符串型
Hash 散列
List 列表
Set 集合
Sorted Set 有序集合
Git
git reset、git revert、git checkout 区别?
相同点:撤销代码仓库中的某些更改
不同点:
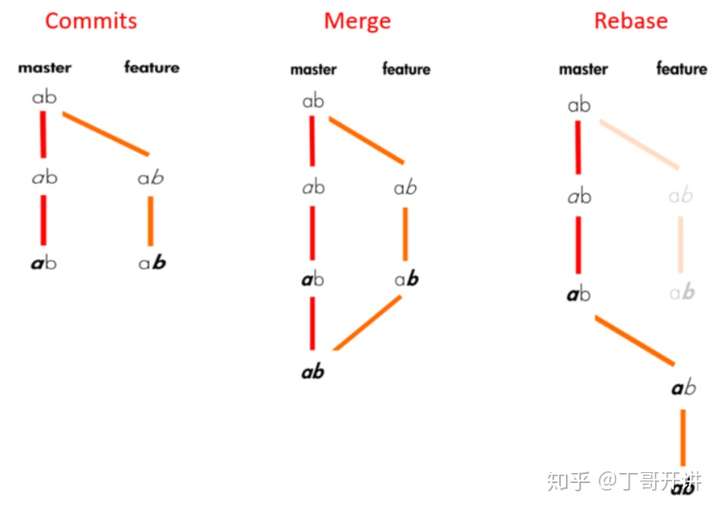
git merge 与 git rebase区别?
相同点:都用于分支合并
merge
特点:
保留有价值的历史记录,不过也会造成支冗余 (小型项目,便于编写过程报告)
rebase
rebase就是变基,改变一条分支的基点,使原分支从指定的节点(commit)延续;
保留了该commit作出的修改,但删除/丢弃了分支上一些现有的提交记录,删去了这些节点
特点:
删减就繁,所以也无法体现时间线 (大型项目,需要生成简洁的线性历史树)
git pull 与 git fetch区别?
相同点:都是把远程分支拉到本地
不同点:
pull=fetch+merge 或者 pull=fetch+rebase (根据配置)
pull: 下拉远程分支并与本地分支合并
fetch:只是下拉分支

单元测试
前端代码测试工具?
Jest
优点:
pm2
介绍下pm2?
管理多个node服务进程(启动,关闭,删除,重启,显示内存状态)
由于nodeJs是单线程执行的,所以主线程抛出一个错误就会退出程序。所以需要守护进程
不用PM2怎么做进程管理?
cluster API: node原生提供,可以创建共享服务端口的子进程
shell脚本启动守护:每次错误后间隔1秒启动服务,定时器检测
node-forever: 崩溃就重启一个
source map
Source Map介绍?
保存源代码映射关系的文件,方便快速定位错误代码
特点:
以.map文件格式结尾
是一个object对象
使用source Map前后对比:
定位了具体的文件名,在源文件中的具体位置(行,方法名)
Source Map实现原理?
主要参数:
version (Number): source map的版本
source (Array) : 打包的原文件路径
names (Array) : 转换前所有的变量和属性名
mappings(String): 记录位置信息的字符串,map和源文件的映射关系 (核心知识点)
file (String): 输出的文件路径
sourcesContent [Array]: 每个文件打包的具体内容
sourceRoot [String] :
Source Map 映射过程:
css中的source map
参考资料:
如何生成source map?
各种主流的前端任务管理工具,打包工具都支持生成Souce Map
( 通过webpack 等工具,生成的代码它跟构建文件同在一个目录下)
Webapck
Grunt
UglifyJS2
Gulp
SystemJS
webpack 开启source map 输出选项
参考资料:
编程实战题
最后更新于
这有帮助吗?