js
js原生
[TOC]
如何判断两个对象是不是相等?
1). 【转成字符串判断】 JSON.stringife(obj);JSON.parse(str)。
注意事项:
如果两个对象的顺序不一致,则两个对象不相等
不支持函数、正则、DOM节点比较
2). 【第三方库:loadsh】: _.isEqual(obj1, obj2);
注意:
不支持函数、正则、DOM节点比较
3). 【自定义-循环遍历】
可以兼容函数,正则等方法
什么是Polyfill?
Polyfill是一块代码(通常是web上的js),为旧浏览器提供它没有原生支持的较新功能;
抚平不同浏览器之间对JS实现的差异
eg:
使用Silverlight 模拟 html canvas元素的功能 或 模拟 CSS实现 rem单位的支持,或text-shadow,其他
一段polyfill代码,为低版本浏览器为Array对象添加forEach方法

什么是函数副作用?
做和这个函数功能不相关的事情,理想状态,一个函数只专注完成一件功能。
常见的副作用
修改了外部的变量(全局变量,内部变量等)
打印到终端
js实例方法与静态方法的区别,如何注入?
静态方法:
可以直接用类名,方法名去调用的
注入方式:
构造函数:
当做属性写入
自执行函数内,返回一个构造函数,当做属性写入也放入自执行函数
class类:在方法/属性前添加static 字段
实例方法:
不能直接调用,必须先实例化才可以调用
注入方式:
对象,通过原型链prototype 注入
在class类方法的默认状态
class类的注入
function函数的注入
构造函数能过自执行函数注入:
堆和栈的区别?
1)相同点:
堆和栈是两种常见的数据结构,主要用于存储程序运行过程的中的变量与数据。
2)不同点
存储位置
栈:线性结构,存储在内存中的栈空间,它的空间是连线的。
堆:树形结构,存储在内容的堆空间,它的空间是离散的。
内存管理方式(空间的分配与回收)
栈:系统自动管理
堆:手动控制(手动申请与释放)
存储的数据类型
栈:基本类型数据,和对象的引用
堆:对象的实例,数组等复合类型数据
存储方式(读取与存储):
栈:先进后出
堆:通过指针来对数据进行存取
栈示意图(先进后出):

堆示意图:
堆栈关系:
【栈】左侧:栈中存放引用地址,这个地址在计算机中叫做引用变量
【堆】右侧:堆中存放对象,多个引用地址会指向同一个对象,JS节省存储空间
代码的复用有哪几种方式?
把相同的代码抽离出来,比如:公共的变量(枚举值),方法,组件等。
函数封装
继承(extend)和多态 :子类可以继承父类的属性和方法,也可以进行扩展和重写。提高代码的抽象性。
模块化的复用:按模块进行拆分,模块功能单一,方便组合和单独测试。
扩展资料:
进程与线程的区别?
尺度划分
大(一个进程至少有一个线程)
小(数量多,并发高)
内存占用
独立内存单元(处理隔离)
共享内存(处理并发,极大提高效率)
根本区别
操作系统资源分配的基本单位
CPU任务调度和执行的基本单位
性能开销
大(程序切换消耗大,独立执行)
小(同一类线程共享代码与数据空间,拥有独立的运行栈和程序计数器(PC)
所处环境
操作系统(可运行进程(程序))
进程 (通过CPU调试,每个时间片中只有一个线程执行)
包含关系
进程包含线程
线程依赖进程
参考资料:
javascript代码中,String('hello')===new String('hello')相等吗,为什么?
不相等。String('hello')返回是一个字符串的字面(是一个string类型),new String返回是字符串类型的对象(object类型)。
如果要比较它们的字面量,需要写成。
扩展资料:
js延迟加载的方式有哪些?
defer和async、动态创建DOM方式(创建script,插入到DOM中,加载完毕后callBack)、按需异步载入js
defer:异步加载,延迟执行(文档解析完成后)
async:异步加载,立即执行

参考资料:
new操作符具体干了什么呢?
1、创建一个空对象,并且 this 变量引用该对象,同时还继承了该函数的原型。 2、属性和方法被加入到 this 引用的对象中。 3、新创建的对象由 this 所引用,并且最后隐式的返回 this 。
var obj = {}; obj.proto = Base.prototype; Base.call(obj);
参考资料:
==与===的区别,并回答下面代码的运行结果?
==与===都是用来比较数组是否相等的。==相比===执行会更麻烦一点。
==会先把两边的数据进行格式转换。
string类型的number转成number。比始把 '1' 转成1,‘0.0’转成0
string类型的非number转换成NaN。 比始 null ,undefined, "a" 都会转成NaN (只要有任意一个值为NaN就不会相等)
boolean类型:true转成1,false转成0
===会先判断数据的类型,再对值进行比较。这是由于js是弱类型语言决定的。像java一些强类型语言,在定义变量是其实已经定义好了类型。所以只要==就可以了。
解释下变量提升?
js引擎的工作方式是,先解析代码,获取所有被声明的变量,然后再一行行地运行。这造成了所有变量的声明语句,都会被提升到代码头部,这就叫做变量提升(hoisting).
变量提升的优点:
提高性能
提升容错
变量提升的缺点:
变量被覆盖
变量没有被销毁 (在函数内部的for循环中定义使用var 定义变量)
eg: 变量被覆盖
参考资料:
js的执行过程?
js特点:异步,单线程;
一、语法分析 js脚本代码块加载完毕后,进入语法分析,判断 语法是不中正确,如果不正确,向外抛出 语法错误(syntaxError), 停止该js代码块的执行,然后继续查找并加载下一个代码块;如果语法正确,则进入预编译阶段
二、预编译阶段
前置知识: js运行环境: - 全局环境:js代码加载完毕后,代码进入全局环境) - 函数环境:函数调用执行时,进入该函数环境,不同函数则函数环境不同 - eval :不建议使用,有安全、性能问题
预编译阶段过程如下:
函数调用栈:
形成执行上下文:进入不同环境创建相应的执行上下,可创建多个
形成函数调用栈:js引擎以栈的形式处理执行上下文 (栈底永远全局执行上下文,栈顶永远是当前执行上下文)
创建执行上下文:
创建变量对象
建立作用域链
确定this指向
三、执行阶段:
可参考: 宏任务与微任务,事件循环event loop介绍
推荐文章:
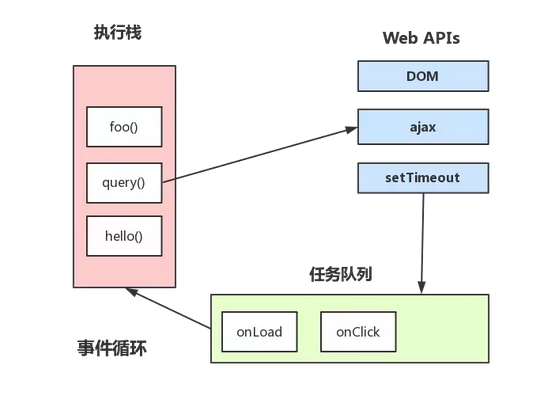
js中的宏任务与微任务,事件循环event loop?
**宏任务(macro-task): **
同步任务 :js引擎按主线程按顺序执行的任务,一个一个任务执行,形成一个执行栈(函数调用栈)
eg:console.log(11); let a=10;
异步任务 :不直接进入js引擎主线程,而是满足条件时触发,相关的线程将该任务推进 任务队列,等待js引擎主线程上的任务执行完毕,再读取执行中的任务
eg:ajax, dom事件,setTimeout
**微任务(micro- task) **
微任务是在es6和node环境中出现的一个任务类型
eg:promise,process.nextTick
js引擎执行过程: 宏任务(同步任务) ---> 微任务 --> 宏任务(异步任务)
柯里化函数的例子,并说明柯里化的好处?
柯里化是一种模式,把一个具有多个参数的函数被分解成多个函数,当被串联调用时,这些函数将一次累加一个所需的所有参数。这种技术有助于使用函数式编写的代码更容易阅读和编写。需要注意的是,要实现一个函数,它需要从一个函数开始,然后分解成一系列函数,每个函数接受一个参数。
优点:
【预置共有参数】
【拆分大的函数】每个函数执行一个独立的任务,能过串联的方式拼接起来
使用场景:
使代码便于理解 //react-redux,connect方法, 将component要用到的state切面和action注入到它的property中,达到ui组件,和容器组件分离的目的。
let Container=connect(mapStateToProps,mapDispatchToProps)(Component);

判断一个变量是不是数组的有哪几种方法?
Object.prototype.toString.call(arg) === '[object Array]' //目前最准确的方法
Array.isArray(arg) //有兼容性问题,IE8下不支持
arg instanceof Array //不能跨iframe使用
arg.constructor===Array //不能跨iframe使用,constructor可以改写, a.constructor=Object; 会导致判断不准确
0.1+0.2 为什么不等于0.3?
浮点数据误差问题,JS中整数与小数都只有一种类型:Number;
它的实现遵循IEEE 754标准,使用64位固定长度表示,就是标准的double双精度浮点数。
这样存储的存储结构优点:归一化处理整数和小数,节省存储空间。
64位比特可分为三个部分:
符号位S: 第1位正负数符号位(sign),0代表正数,1代表负数;
指数位E:中间的11位存储指数(exponent),用来表示次方数;
尾数位M:最后52位是尾数(mantissa),超出的部分自动进一舍零;


数学工式如上图:
4.5 转换过程
比较10进制的4.5转换成2进制就是 100.1
科学计数法表示注是(二进制) 1.001*2^2
舍去1后,M=001;
E=1025
如何解决js 精度计算问题?
产生的原因:
浮点数计算精度问题
大数精度问题
解决思路:
把浮点型数值转成整型计算
将浮点数转化成字符串,模拟运算过程 // 成熟库的使用方法
类库:
Math.js
bignumber.js
哪些操作会造成内存泄漏?
内存泄漏原因:不再用到的内存,没有及时释放,就叫做内存泄漏;
全局变量缓存数据 (无法被垃圾回收机制收集)
定时器没有清除
闭包的循环引用
js错误引用dom元素 (dom虽然删除,但是引用还在内存中)
js垃圾回收机制?
引用计数 (如果没有引用指向该对象,对象将被垃圾回收机制回收,缺点:在循环引用的情况下,存在局限性)
标记清除 (处理循环引用的问题,和引用计数本质相同,可达内存被标记,其余的被当作垃圾回收)
null,undefined区别?分别会在什么情况下出现?
null:代表无的状态,此处不应该有值 ---(之前没定义这个变量,就是null)---作用对象原形的终点
undefined:代表未找到,缺少值---(之前定义了,却没有赋值就是undefined)---变量赋值,函数传参
js语言的特点?
答:异步,单线程,事件驱动,解释性语言,弱类型;
什么是作用域链?
作用域链就是【变量】和【函数】和可访问范围,
控制着变量和函数的可见性与生命周期,在js中变量的作用域有全局作用域和局部作用域 ;
什么是块级作用域?
定义:是指包裹在一对 {...} 花括号中的区域,在该区域定义的变量和函数只在此区域有效,出了该区域无法访问。
在js中定义块级使用域的方法:
function
class
let, const 定义的变量 (for循环中定义)
其他的一些定义块级使用域的方法
Try, catch
使用块级使用域有什么好处?
参考资料:
什么是闭包,如何使用,闭包有什么问题?
闭包是由函数创建的一个词法作用域,里面的变量被引用后(外部函数引用,前提得先return出来),可以在这个词法环境之外使用;
函数嵌套函数,能够读取【其他函数】内部变量的【函数】;
闭包一定得return才能读取内部的值;
闭包的原理就是作用域链
用途
创建内部变量,使得这些变量不能随意被外部修改,但是又可以通过指定的函数接口修改
减少全局变量
让这些值始终保持在内存中
闭包的问题:
耗性能:闭包会使函数内的变量一直保持在内存当中,
解决:在退出函数之前,将不使用的函数变量全部删除;
//使用自执行函数写法
//使用new写法
如何获取闭包函数内的变量?
函数嵌套,闭包
函数返回值,return
js有哪几种数据类型?
js一共七种类型;
基本类型(6):String,Boolean,Number,Undefined,Null,Symbol(创建唯一的值)
引用类型(1):Object(Function,Array, Date, RegExp)
js如何判断数据类型?
typeof :
不能判断的类型:Array ,Object,Null,Date, Regexp正则;
可以判断的类型:number,string,boolean, undefined, function, symbol
instanceof :可以用来判断数组; [1] instanceof Array 返回 true
toString: Object.prototype.toString.call([]) 返回true
可以判断所有的类型
constructor: [].constructor===Array 返回true
isArray:数组专用判断方法 Array.isArray([])
只能判断数组
// 使用Object原型链上的toString方法判断数据类型
// 判断变量是数组的四种方法
js有哪些内置对象?
object是js中所有对象的父对象;
数据封闭类对象:object,array,boolean,number,string
其他对象:function,arguments,math,date,RegExp,error
js如何实现继承?
通过原型链(prototype)来实现
通过构造函数继承-(在子函数中使用)
es6的class,配合extend来实现继承
拷贝继承(创建一个extendFun的方法)
es5的继承和es6继承的区别?
es5继承本质:
先创建子类的实例对象
再将父类的方法挂载到this上; parent.apply(this);
es6的继承本质 (es6通过class定义类,能过extend继承类,子类必须在construct 方法中调用super,否则新建实例报错,因为子类没有自己的this,而是继承了父类的this, 然后对其进行加工,如不调用super, 子类得不到this对象)
先创建父类的实例对象this (所以先调用父类的super方法)
然后再用子类的构造函数修改this
前端路由实现原理?
前端实现路由有两种方式:
1) history模式
主要借助html5的两个api,
window.history.pushState("/detail") //添加历史记录
window.history.replaceState("/detail") //替换当前历史记录
两个 API 都会操作浏览器的历史记录,而不会引起页面的刷新。
2) hash模式
实现的api:
监听哈希变化触发的事件( hashchange) 事件,
window.location 处理哈希的改变时不会重新渲染页面
介绍下链式调用,如何实现,链式调用有什么优势?
链式调用是一种编程模式,它允许我们在一个对象上连续的调用多个方法。在一条语句上执行多条命令。并且可以在链式调用中添加或删除方法来快速修改代码。
链式调用的实现原理:在对象方法的结尾都返回对象本身(即this), 从而使对象的下一个方法能直接使用该对象。这种方式可以在多个对象之间传递数据和状态,让代码更简洁和易于阅读。
使用链式调用的优点:
让代码更简洁:一条语句可以实现多个功能,让代码更易读,提高可维护性。
减少执行时间和内存占用:因为一条语句中完成了多个操作,避免了内存的重新计算和分配。
知名的几个库都用到了链式调用的方式:
jquery
lodash
原型对象,构造函数,实例之间有什么样的关系?
原型对象:js中每个对象都拥有原型对象,它是js中实现继承的一种机制。每个对象都包含属性和方法,每个子对象可以通过原型链继承这些属性和方法。
构造函数:是一种特殊的函数,相当于模板。
实例:通过构造函数这个模板,调用new方法,创建一个具体的对象。每个实例都是独立的,具有自己的属性和方法。但是他们都可以访问原型对象上的属性和方法,达到代码的复用(节省内存占用)。
函数
函数定义有哪几种方式,它们之间有什么区别?
函数定义有三种定义方式,语法如下
函数声明:
function sum(a,b){return a+b};
函数表达式:形式类似普通变量的初始化
普通函数:const sum=function fn(a, b){ return a+b }; const sum=fn (a,b)=>{ return a+b } // 特别说明:fn是函数内部的局部变量,外部无法直接读取,所以直接调用fn(1,2)会报变量未定义。
匿名函数:const sum=function(a,b){ return a+b }, const sum=(a,b)=>{ return a+b }
构造函数(Function()): const add = new Function('a', 'b', 'return a + b')
它们之间的区别主要在,变量提升和名称上面:
函数声明:存在变量提升
函数表达式:不存在变量提升,函数名称是可选的(可以定成匿名函数)
构造函数:不存在变量提升,名称是必须的
函数调用有几种方式?
函数调用有五种模式
函数调用模式
add(1,2);方法调用模式 :
obj.add(1,2);构造器调用模式 :
const p=new People(); p.getName();Call(), apply()调用:
add.apply(null, [1,2]),add.apply(null, 1,2)匿名函数调用模式
((num1,num2)=>{console.log(num1+num2)})(1,2)
参考资料:
https://weread.qq.com/web/reader/2ba32920720a57e92ba5389k34132fc02293416a75f431d
什么是构造函数,它和普通函数有什么区别,主要用在哪些场景?
构造函数是通过new关键词生成的函数,构造函数约定首字母大写,为了和普通函数区分开。
语法如下: const add = new Function('a', 'b', 'return a + b') // 函数的最后一个参数是函数执行体,其他参数都是实参。
区别:
调用方式:
构造函数:需要通过new关键字,创建一个实例,再调用。
普通函数:直接调用函数的实体。
返回值:
构造函数:隐式的返回函数的实体
普通函数:需要手动,显示的返回值(返回值是可选的)
目的:
构造函数:创建新的对象
普通函数:执行一些任务(数据格式转换,修改变量的值,获取特定的值)或计算结果
demo展示
函数内部的arguments对象的有什么用,有哪些使用场景?
arguments可以获取传入函数的实际参数,而不是函数定义的参数。
arguments对象是一个类数组的对象。
使用场景:
用来判断入参个数据是否正确
用来处理任意个数的入参,比始多个参数拼接等
模拟函数的重载
性能优化:
如何进行性能优化?
减少网络请求(大小,数量)---网络会有延迟,大部分浏览器一性能获取6-8个请求:
资源合并/代码压缩:js,图片(webP,base64),css
降低CPU消耗
减少DOM操作:缓存DOM查询,合拼DOM插入,事件节流
缓存:保持名字不变,如果要改变可以使用hash来改变
加速服务端资源返回的速度:
cdn(千牛,bootcdn)
懒加载(主要处理图片,默认图片代码真实图片)
SSR后端渲染
图片懒加载的实现原理?
原理:img src中放入一张很小的图片,把真实的图片放在img的属性中,data-src, 通过监听页面滚动过程中,图片距离顶部的高度来设置页面是否显示;

一般可以使用
jquery.lazyload.js //到了可视区才加载
lazysizes.js //没有到可视区才显示功能,不依赖jquery
注意事项:
使用节流函数进行性能优化
如何在js中实现不可变对象?
深拷贝,性能非常差,不适合大规模使用
immutable.js,自成一体的一套数据结构,性能良好,但是学习额外的api
immer,利用proxy特性,无需学习额外的api,性能良好
immutable实现原理?
原理:持久化数据结构,结构共享,只修改对象树中变化的节点和受它影响的父节点,其它节点共享;
immutable data就是一旦创建,就不能再被更改的数据。对immutable对象的任何修改或添加/删除操作都会返回一个新的immutable对象。
优点:
降低mutable 可变对象的复杂度
节省内存空间 (不用深拷贝对象,共享结构,没有被引用的对象会被垃圾回收)
数据回退,任意穿越(每次数据都是不一样的,只要把这些数据放在一个数组中储存起来,可任意回退)
拥抱函数式编程,关心数据的映射,命令式编程关心解决问题的步骤,函数式编程比命令式编程更适用于前端开发。因为只要输入一致,输出必然一致,这样开的组件更易于调试和组装。
缺点
容易与原生对象混
什么是重排什么是重绘?
DOM的结构属性改变就会触发重排或者重绘;
只改变DOM节点对象的css的颜色,不改变大小,其他排版属性就属于重绘;
visibility:hidden,隐藏dom节点只触发重绘,display:none隐藏dom节点触发重排和重绘;
改变padding会触发:重排+重绘
什么是深拷贝和浅拷贝,如何实现深拷贝?
js中数据类型分为2类,引用数据类型(array,object,function),和其他数据类型(string,number,boolean,null,undefind);
深拷贝指拷贝后的对象与原来的对象相互独立,修改任何一方,其他一方都不受影响;
深拷贝主要有
es6的 spread展开,可以深拷贝数组,对象;
for循环依次读取复制
先通过JSON.stringify把对象转化成字符串,再通过 JSON.parse把字符串转换成对象 (如果对象中包含函数,正则表达式会丢失;对象有循环引用会报错;)
外部库:jquery extend, 使用标准库 lodash的 cloneDeep
注意事项:
Object.assign 只能深拷贝第一层,深层的还是浅拷贝;
深拷贝方法:jquery的extend
什么是事件节流和函数防抖的区别,和实际运用?
相同点:为了限制函数执行的次数 ,导致的性能浪费;
不同点:
事件节流throttle:指定时间周期内,只能执行一次;
运用
滚动到底部触发事件
函数防抖 debounce:指定时间周期后,才能执行此函数, 如果这周期内重复触发,就会重新开始计算
输入框实时搜索
window resize
长列表优化?
思路:虚拟列表
只显示部分数据
通过监听滚动条的位置(向上滚动/向下)来进行,来进行对数组进行动态替换
顶部使用padding来代替
介绍下PWA,为什么service worker 可以提高性能 ?
定义:pwa渐近式增弹网页应用
PWA特点:
拥有桌面入口,可安装
原生应用界面: //在manifest文件中配置,自定义桌面图标/导航栏颜色
可离线访问 ,需要Https环境 //本地环境localhost也可以调试
支持Push推送
后台加载,哪怕页面关闭,pwa仍然可以在后台运行获取数据(有限制) //哪怕chrome关闭
service worker是html5中的api,它在web worker的基础上加了持久缓存和网络代理能力,结合cache api面向提供了js来操作浏览器缓存的能力。service worker接管网页请求,做为中间层;
service worker特点:
拥有独立的执行线程,单独的作用域范围,单独的运行环境,有自己独立的context上下文。
由于有独立线程,service worker不能直接操作页面DOM。但可以通过事件机制来处理,例如使用postMessage
canvas
canvas与svg区别?
历史:svg有十多年历史,并不是html5专用标签;
展示效果:svg导出后的效果是矢量图形,而canvas显示效果是位图(所以canvas可以引入图片)
技术原理:svg(XML文档)是通过html绘制--可以使用DOM操作,canvas通过js绘制;
canvas支持颜色较svg多;
使用案例:svg(百度地图),canvas(图表)
canvas 与webGL的关系?
canvas就是一个画布,可以在canvas上获取2D上下文和3D上下文,其中3D上下文一般就是webGL.
webGL 是使用 js去调用部分封装过的OpenGL es2.0 标准接口,去提供硬件级别的3D图形加速功能。
三都的关系 : javascript-> webGL -> OpenGL -> ... -> 显卡 并 把最终渲染出来的图形呈现在canvas
webGL常用库:
three.js //在浏览器绘制3D的js库,底层是webGL ( three.js会对不支持的浏览器做降级方案,使用casnvas 2D api处理, 有两个Rennderer ,,webGLRenderer, CanvasRenderer
canvas常用库:
echarts //图表(柱状图、饼图、K线图、雷达图、热力图、关系图、树图、漏斗图、仪表盘、地图),也有使用webGL的3D图形
antV //阿里开的图形引擎
js事件
js事件机制?
javascript是事件驱动型语言,网页上的任意操作(键盘,鼠标)会产生一个“事件”(event),当事件发现时,可以对事件进行响应,具体如何响应某个事件由事件处理函数完成。
1)事件流
事件流描述的是从页面中接受事件的顺序
DOM事件流的三个阶段:
捕获阶段:先调用捕获阶段的处理函数 btn.addEventListen('click'),事件从window对象自上而下向目标节点传播的阶段;
目标阶段:调用目标阶段的处理函数 ;
冒泡阶段:调用冒泡阶段的处理函数,事件从目标节点自下而上向window对象传播的阶段;
bug说明 :下图中缺少:html标签
2)DOM事件级别
DOM级别分为四级,由于DOM1中没有事件相关的内容,即没有DOM1级事件,所以DOM事件分为3个级别,分别是:DOM 0/2/3
DOM0:
DOM2: el.addEventListener(eventName,callback,useCapture)
click事件
DOM3: 在DOM2的基础上,增加更多的事件类型
UI事件:load、scroll
焦点事件:blur、focus
鼠标事件:dbclick、mouseup
键盘事件:keydown、keypress
.....
说明:DOM3级事件允许使用者自定义一些事件
参考:js事件原理、事件委托、事件冒泡和事件绑定 addEventListener
3)事件代理
请参考:什么是事件委托/事件代理?
4)事件对象
event
event.preventDefault() //阻止默认行为
event.stoppropagation() //阻止事件冒泡
event.target & event.currentTarget //目标对象,target指向事件真正的发出者,currentTarget指向监听事件者
5)铺获与冒泡的顺序问题
绑定多个DOM事件,先注册先执行
参考资料: 浏览器事件系统
什么是事件委托/事件代理?
事件委托就是利用事件冒泡,只指定一个事件处理程序,就可以管理某一类型的所有事件,利用父级去触发子级的事件;
优点:
节省内存占用,减少事件注册
新增子对象时,无需再次对其绑定事件,适合动态添加元素
缺点(局限性):
focus,blur 事件本身没有事件冒泡机制,所以无法委托
mousemove,mouseout,需要不断通过位置去计算定位,对性能消耗高,不适合事件委托
层级过多,冒泡过程中可能被某层阻止掉(建议就近委托)
跨域
如何解决跨域的问题?
CORS: 跨域资源共享,关键在于服务端设置, Access-Contorl-Allow-Origin 后台设置允许跨域访问的url;使用额外的HTTP头告诉浏览器
nginx反向代理:修改nginx.conf文件
nodejs中间件代理(webpack本地启动服务使用),在服务端拿到数据后,再把数据返回给前端
websocket协议跨域
通过jsonp(淘汰)
postMessage,可以实现多个页面之间的通讯(html5中的一个api)
其他不常用
window.name : 通能过给一个设置window.name, 能过location.href的时候另外一个页面可以获取到相关数据,刷新也能;局限性:只能设置string类型
document.domain
参考资料:
http://blog.alanwu.website/2020/03/06/crossOrigin/ https://www.jianshu.com/p/835bc9534281
jsonp介绍、原理?
利用script标签没有跨域限制,来达到第三方通讯的目的,需要后端配合
jsonp 的解释,第三方产生的响应为json数据的包装,即json padding
步骤:
【发送请求】:发送请求,携带返回数据的包装方法
【返回数据】后端返回数据,使用cb包装数据
【执行前端方法】前端加载完数据,调用本地已经封装好的cb方法,获取到回调的数据
form表单可以跨域吗?
可以;
跨域的唯一标准,就是你不能通过请求的方式拿到别人内容;
form表单只是发请求,而不是获取数据;
ajax一直在等待别人的done or fail 这就涉及到拿别人数据;
this
bind,call,apply的区别?
共用点:
改变函数执行时的上下文,再具体点就是改变函数运行时this的指向
三者第一个参数都是this要指向的对象,如果未传入,默认指向全局window
三者都可以传入参数
不同点:写法不一样
bind: fn.bind(thisArg,队列or数组)()
call: fn.call(thisArg, arg1, arg2,...)
apply: fn.apply(thisArg, [argsArray])
可以做的几个事:
求数组中的最大和最小值;
利用call和apply做继承
call, apply的其他妙用?
call,apply主要用来改变this指向的。同时apply也可以用来改变函数的入参。
比始:apply函数可以把接收到的数组,展开后再传递给执行函数。
apply: 求数组最大、最小值。 // 其实用ES6的展示方法更好用
apply,call,bind: 把类数组转换成数据
apply ,call : 实现继承,继承父类的属性和方法
参考资料:
https://weread.qq.com/web/reader/2ba32920720a57e92ba5389k03a32a4023f03afdbd66a39
this的指向问题?
this 是函数运行时所在的环境对象
this用法的四种情况:
纯粹的函数调用
作用对象方法的调用
作为构造函数调用
apply调用
this的指向原则:
this永远指向一个对象
this指向完全取决于函数调用的位置
参考:
apply,call区别?
apply,call作用都是改变this的指向,只是参数写入的不同
apply把参数放入一个数组当中 ;
call把参数依次写入;
API
String api?
属性:
长度:length
方法
增:
前/后:+
中间:
索引:先切割(str.slice(startIndex,endIndex)),再拼装
字符(首个,全部): str.replace(new RegExp(targetStr,'g'),targetStr+addStr);
删:
指定字符: replace+正则替换为空
指定索引删除:str.slice(startIndex,endIndex)
改:
正则替换
查(遍历):
判断
是否包含指定字符串: includes
是否以指定字符串(开始/结尾),可指定开始位置:startsWith,endsWith
查询
索引:
-指定索引的字符,chatAt
类数组的方式: str[index]
字符
(首次/最后一次)出现的索引: indexOf, lastIndexOf
统计:出现的总次数, split分隔后数组长度-1
返回指定符:substring(支持负数): 两个索引之间
其他操作:
重复:repeat
去除空格(开头+结尾): trim
转成小/大字母:toLowerCase/toUpperCase
Array api?
原型方法
方法:
Array.from(): 把类数组/可迭代对象中创建一个新的数组实例
Array.isArray(); //判断某个变量是否是数组对象
Array.of(val1,val2) //创建数组 ,相当于 [val1,val2]
属性:
Array.length: //不常用
实例属性:
长度:length
实例方法:
定义:
字面量赋值:let arr=['a'
构造函数:let arr=new Array(['a']);
增加:
开头(可支持多个参数):arr.unshift(val1,val2);
尾部 :arr.push('a')
中间:
指定索引位置增加:arr.splice(fromIndex,0,val1,val2)
指定元素后面添加:使用indexOf找到索引,再能过 arr.splice(fromIndex,0,val1,val2) 遍历添加
删除:
开头:arr.shift(), 返回被删除的元素,改变原数据
结尾:arr.pop(), 返回被删除的元素,改变原数组;
中间(对原数组没影响):arr.splice(startIndex,deleteNum,addNewValue) //在指定索引位置删除元素
修改
索引:arr[0]='a'
查询:
判断:
是否包含:arr.include('a')
满足某个条件:
some(有一个满足条件)
every(所有都满足条件)
findIndex(满足条件的第一个索引)
索引:arr.indexOf('a')
遍历:
不修改原对象:
forEach: 返回的是经过处理后的数组,长度不变
reduce(reduceRight): 可返回任意值,(遍历->处理并返回)
修改原对象:filter ,map
其他:
填充 : arr.fill(value,start,end) 用一个固定值填充一个数组中,从起始索引(包含)到终止索引(不包含)内的全部元素。
元素翻转:arr.reverse(); //原数组改变
排序:arr.sort();
连接:arr.join('-'),按照指定链接符号, 把array转出一个string
切割:arr.slice(startIndex,endIndex); startIndex包含,endIndex不包含;//返回被切割后的数组(对原数组的浅拷贝),不影响原数据
获取对象所有的keys(Array Iterator对象): keys, 要使用 for(const key of iterator){console.log(key)} 才能查看,直接打印就是一个空的{}
Object Api?
构造函数属性:
Object.length //值为1
Object.prototype //可为所有Object类型对象添加属性
构造函数方法:
实例属性(object.prototype对象上):
constructor : 特定函数,用于创建对象的原型
proto : (被冻结,禁止修改)指向当对象被实例化的时候,用作原型对象
实例方法:
toString: (不常用)返回对象的字符串表示
hasOwnProperty: 判断对象自身属性(非原型链继承),返回boolean
Function Api?
原型属性(Function):
arguments : 以数组形式获取传入函数的所有函数
name : 获取函数的名称
实例属性(Function):
constructor : 声明函数的原型构造方法
实例方法(Function.prototype):
apply
bind
call
Number Api?
原型Number(属性):
原型Number(方法):
判断值是不是NaN: isNaN
判断是不是有穷数:isFinite
判断是不是整数: isInteger
Math Api?
原型方法(Math):
绝对值: abs(x)
随机数:返回0到1之间的伪随机数据,random
向上/下取整: ceil/floor
次幂: pow(4,3) //4x4x4 等于 4的3次幂
js 全局 函数?
全局属性:
无穷大:Infinity , -Infinity //正/负 无穷大
未定义:undefined
NaN
全局函数
解析字符串并返回整数/浮点数:parseInt,parseFloat
把对象的值转成数字:Number
把对象的值转成字符串:String
重新运算参数的内容: eval
判断某个值是不是数字:isNaN
判断某个值是否为无穷大:isFinite //有限的返回true,无穷返回false, NaN返回false
编码/解码URI: encodeURI, decodeURI
编码/解码URI: encodeURIComponent, decodeURIComponent
最后更新于
这有帮助吗?